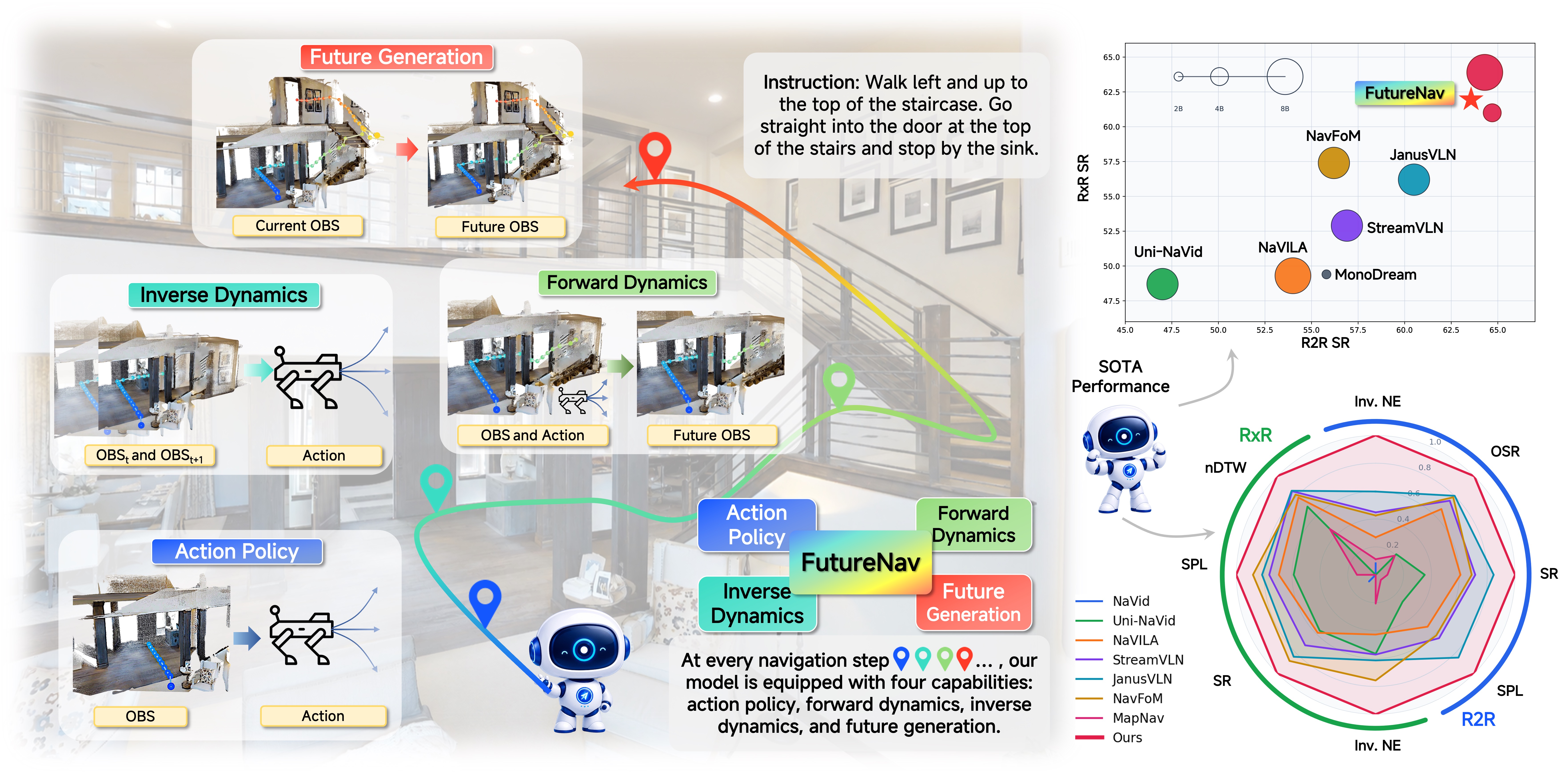
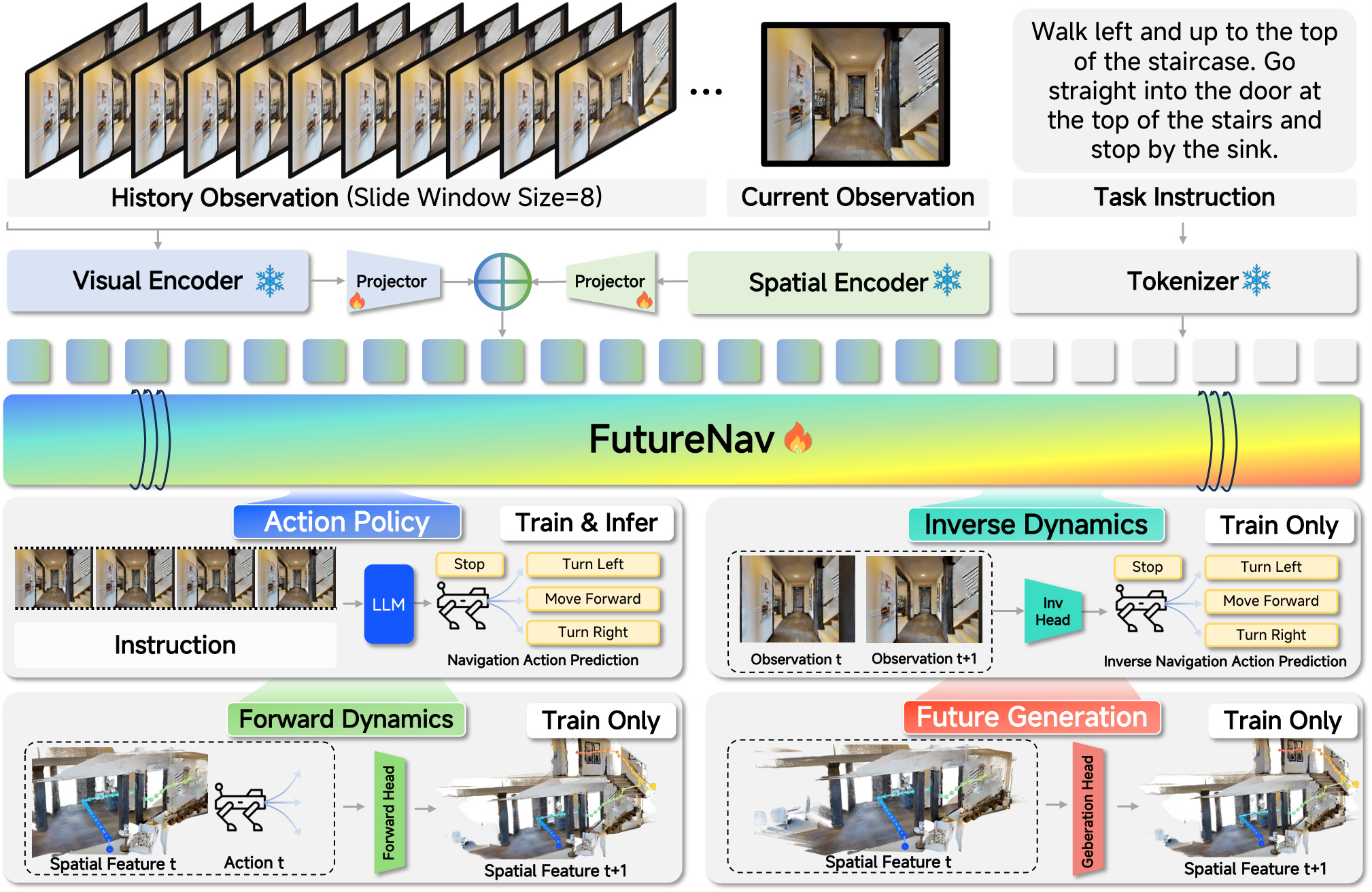
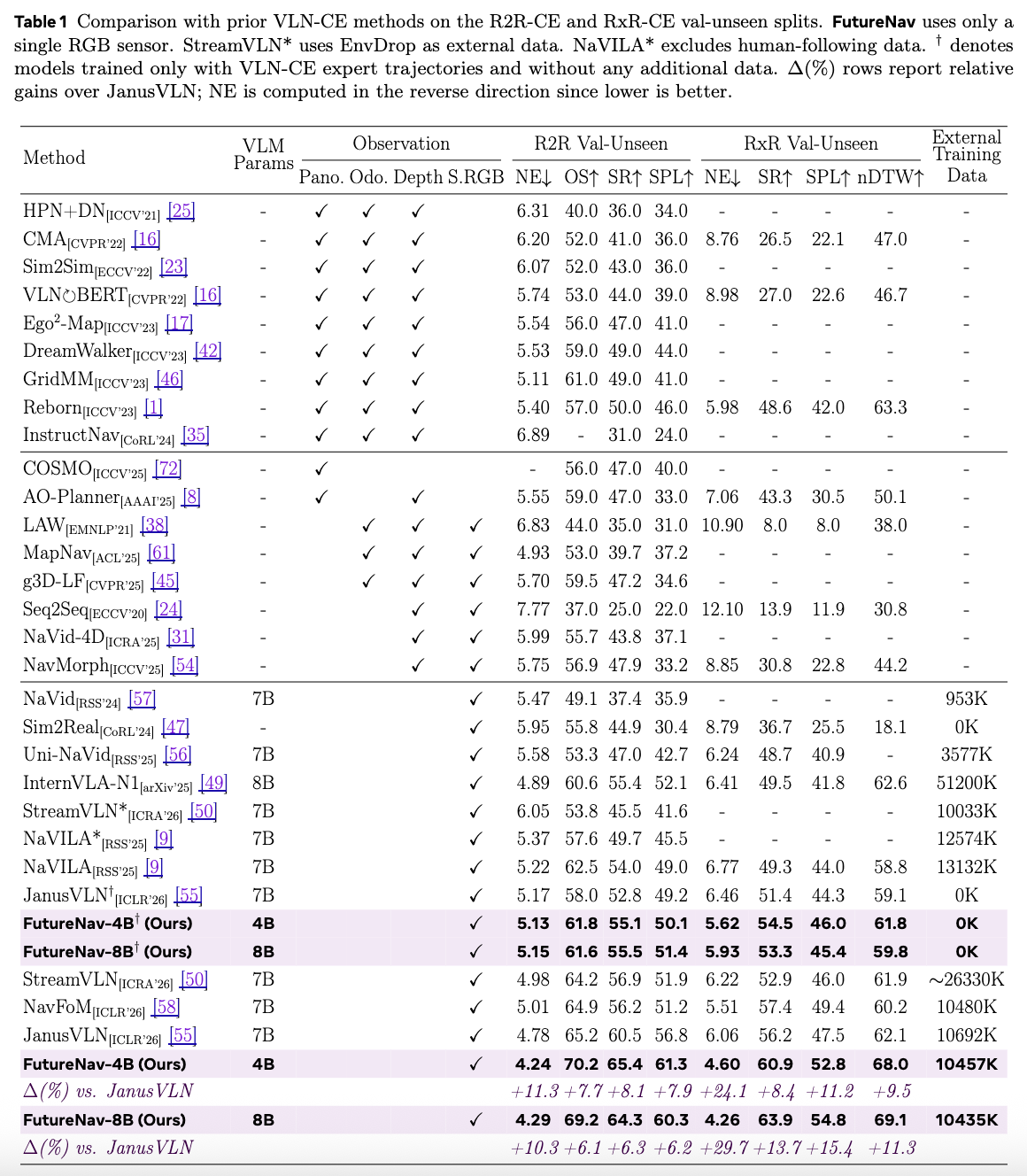
Vision-and-language navigation (VLN) in continuous environments requires an agent to
ground instructions in egocentric observations while maintaining spatial
understanding across long action sequences. Recent navigation foundation models
have shown strong progress by scaling vision-language models, but they often
learn navigation primarily as direct action generation, without explicitly
modeling world states or predicting their future evolution. We introduce
\emph{Unified Navigation World Action Model} (FutureNav), a VLM-based unified
world-action modeling framework. Specifically, FutureNav jointly encodes text,
visual, and spatial features and feeds them into the LLM, and optimizes four
objectives for simultaneous world and action modeling: an action policy objective
for navigation action prediction, inverse and forward dynamics objectives for
modeling state transitions, and a future generation objective for predicting
future spatial states. This unified architecture strengthens action prediction
while explicitly modeling the world, without sacrificing inference speed.
Extensive experiments show that, with only a 4B-scale backbone, FutureNav
achieves state-of-the-art performance on multiple VLN benchmarks and
substantially outperforms prior VLN methods, paving the way toward future
world-action models for VLN. We will release the code and models to support
future research.